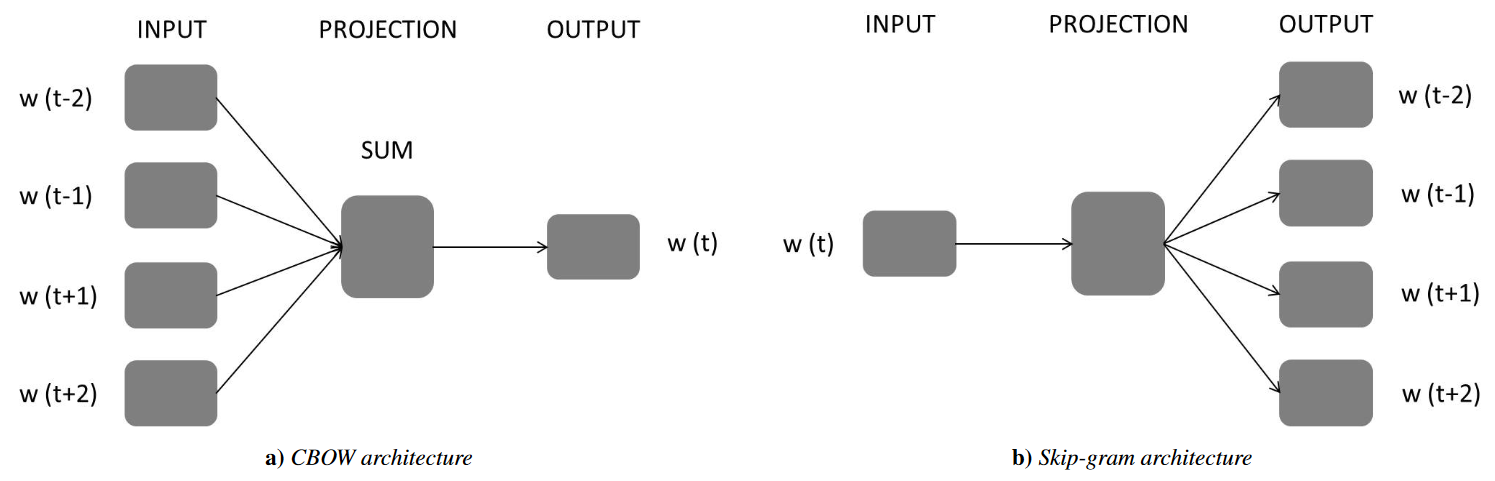
Extensions and Variants
There are quite a few variants of RDF2vec which have been examined in the past.
- Walking RDF and OWL pursues exactly the same idea as RDF2vec, and the two can be considered identical. It uses random walks and Skip Gram embeddings. The approach has been developed at the same time as RDF2vec. [Alsharani et al., 2017]
- KG2vec pursues a similar idea as RDF2vec by first transforming the directed, labeled RDF graph into an undirected, unlabeled graph (using nodes for the relations) and then extracting walks from that transformed graph. [Wang et al., 2021] Although no direct comparison is available, we assume that the embeddings are comparable.
- Wembedder is a simplified version of RDF2vec which uses the raw triples of a knowledge graph as input to the word2vec implementation, instead of random walks. It serves pre-computed vectors for Wikidata. [Nielsen, 2017]
- KG2vec (not to be confused with the aforementioned approach also named KG2vec) follows the same idea of using triples as input to a Skip-Gram algorithm. [Soru et al., 2018]
- Triple2Vec follows a similar idea of walk-based embedding generation, but embeds entire triples instead of nodes. [Fionda and Pirrò, 2020]
- [Van and Lee, 2023] propose different extensions to creating walks for RDF2vec, including the usage of text literals by means of creating new graph nodes for similar text literals, as well as the introduction of latent walks which capture relations which are not explicit in the knowledge graph.
- RDFstar2vec is an extension of RDF2vec which works on RDF-star graphs. It defines additional walk strategies for quoted triples. [Egami et al., 2023]
Natively, RDF2vec does not incorporate literals. However, they can be incorporated with a few tricks:
- PyRDF2vec (see above) has an option which adds literals of entities as direct features, creating a heterogeneous feature vector consisting of the embedding dimensions and additional features from the literal values.
- There are quite a few graph preprocessing operators which can be utilized to incorporate literals by representing their information in the form entities and relations, so that they are processed by RDF2vec (and other embedding methods). Even simple baselines which are efficient and do not increase the graph size can boost the performance of RDF2vec. [Preisner and Paulheim, 2023]
RDF2vec supports Knowledge Graph Updates.
Most knowledge graph embedding methods do not support knowledge graph updates and require re-training a model from scratch when a knowledge graph changes. Since word2vec provides a mechanism for updating word vectors and also learning vectors for new words, RDF2vec is capable of adapting its vectors upon updates in the knowledge graph without a full retraining. The adaptation can be performed in a fraction of the time a full retraining would take. [Hahn and Paulheim, 2024]
Initially, word2vec was created for natural language, which shows a bit of variety with respect to word ordering. In contrast, walks extracted from graphs are different.
Consider, for example, the case of creating embedding vectors for
bread in sentences such as
Tom ate bread yesterday morning and
Yesterday morning, Tom ate bread. For walks extracted from graphs, however, it makes a difference whether a predicate appears before or after the entity at hand. Consider the example
above, where all three entities in the middle (
Angela_Merkel,
Peter_Tschentscher, and
Germany) share the same context items (i.e.,
Hamburg and
leader). However, for the semantics of an entity, it makes a difference whether that entity
is or
has a leader.
RDF2vec always generates embedding vectors for an entire knowledge graph. In many practical cases, however, we only need vectors for a small set of target entities. In such cases, generating vectors for an entire large graph like DBpedia would not be a practical solution.
- RDF2vec Light is an alternative which can be used in such scenarios. It only creates random walks on a subset of the knowledge graph and can produce embedding vectors for a target subset of entities fast. In many cases, the results are competitive with those achieved with embeddings of the full graph. [Portisch et al., 2020] Details about the implementation are found here.
- LODVec uses the same mechanism as RDF2vec Light, but creates sequences across different datasets by exploiting owl:sameAs links, and unifying classes and predicates by exploiting owl:equivalentClass and owl:equivalentProperty definitions. [Mountantonakis and Tzitzikas, 2021]
RDF2vec can explicitly trade off similarity and relatedness.
One of the key findings of the comparison of RDF2vec to embedding approaches for link prediction, such as TransE, is that while embedding approaches for link prediction create an embedding space in which the distance metric encodes similarity of entities, the distance metric in the RDF2vec embedding space mixes similarity and relatedness [Portisch et al., 2022]. This behavior can be influenced by changing the walk strategy, thereby creating embedding spaces which explicitly emphasize similarity or relatedness. The corresponding walk strategies are called p-walks and e-walks. In the above example, a set of p-walks would be:
birthPlace -> country -> Germany -> leader -> birthPlace
country -> leader -> Angela_Merkel -> birthPlace -> leader
residence -> leader -> Peter_Tschentscher -> residence -> leader
Likewise, the set of e-walks would be
Peter_Tschentscher -> Hamburg -> Germany -> Angela_Merkel -> Hamburg
Hamburg -> Germany -> Angela_Merkel -> Hamburg -> Peter_Tschentscher
Angela_Merkel -> Hamburg -> Peter_Tschentscher -> Hamburg -> Germany
It has been shown that embedding vectors computed based on e-walks create a vector space encoding relatedness, while embedding vectors computed based on p-walks create a vector space encoding similarity. [Portisch and Paulheim, 2022]
Besides e-walks and p-walks, the creation of walks is the aspect of RDF2vec which has been undergone the most extensive research so far. While the original implementation uses random walks, alternatives have been explored include:
- The use of different heuristics for biasing the walks, e.g., prefering edges with more/less frequent predicates, prefering links to nodes with higher/lower PageRank, etc. An extensive study is available in [Cochez et al., 2017a].
- Zhang et al. also propose a different weighting scheme based on Metropolis-Hastings random walks, which reduces the probability of transitioning to a node with high degree and aims at a more balanced distribution of nodes in the walks. [Zhang et al., 2022]
- A similar approach is analyzed in [Al Taweel and Paulheim, 2020], where embeddings for DBpedia are trained with external edge weights derived from page transition probabilities in Wikipedia.
- In [Vandewiele et al., 2020], we have analyzed different alternatives to using random walks, such as walk strategies with teleportation within communities. While random walks are usually a good choice, there are scenarios in which other walking strategies are superior.
- In [Saeed and Prasanna, 2018], the identification of specific properties for groups of entities is discussed as a means to find task-specific edge weights.
- Similarly, NESP computes semantic similarities between relations in order to create semantically coherent walks. Moreover, the approach foresees refining an existing embedding space by bringing more closely related entities closer together. [Chekol and Pirrò, 2020]
- Mukherjee et al. [Mukherjee et al., 2019] also observe that biasing the walks with prior knowledge on relevant properties and classes for a domain can improve the results obtained with RDF2vec.
- The ontowalk2vec approach [Gkotse, 2020] combines the random walk strategies of RDF2vec and node2vec, and trains a language model on the union of both walk sets.
Besides changing the walk creation itself, there are also approaches for incorporating additional information in the walks:
- [Bachhofner et al., 2021] discuss the inclusion of metadata, such as provenance information, in the walks in order to improve the resulting embeddings.
- [Pietrasik and Reformat, 2023] introduce a heuristic reduction based on probabilistic properties of the knowledge graph as a preprocessing step, so that a first version of the embedding can be computed on a reduced knowledge graph.
RDF2vec relies on the word2vec embedding mechanism. However, other word embedding approaches have also been discussed.
- In his master's thesis, Agozzino discuss the usage of FastText and BERT in RDF2vec as an alternative to word2vec. His preliminary experiments suggest that FastText might be a superior alternative to word2vec. [Agozzino, 2021] The FastText variant is also available in the pyRDF2vec implementation.
- KGlove adapts the GloVe algorithm [Pennington et al., 2014] for creating the embedding vectors [Cochez et al., 2017b]. However, KGlove does not use random walks, but derives the co-occurence matrix directly from the knowledge graph.
While the original RDF2vec approach is agnostic to the type of knowledge encoded in RDF, it is also possible to extend the approach to specific types of datasets.
To materialize or not to materialize? While it might look like a good idea to enrich the knowledge graph with implicit knowledge before training the embeddings, experimental results show that materializing implicit knowledge actually makes the resulting embedding worse, not better.
- In [Iana and Paulheim, 2020], we have conducted a series of experiments training embeddings on DBpedia as is, vs. training embeddings on DBpedia with implicit knowledge materialized. In most settings, the results on downstream tasks get worse when adding implicit knowledge. Our hypothesis is that missing information in many knowledge graphs is not missing at random, but a signal of lesser importance, and that signal is canceled out by materialization. A similar observation was made by [Alsharani et al., 2017].
RDF2vec can only learn that two entities is similar based on signals that can co-appear in a graph walk. For that reason, it is, for example, impossible to learn that two entities are similar because they have an ingoing edge from an entity of the same type (see also the results on the DLCC node classification benchmark [Portisch and Paulheim, 2022]). Looking at the following triples:
:Germany rdf:type :EuropeanCountry .
:Germany :capital :Berlin .
:France rdf:type :EuropeanCountry .
:France :capital :Paris .
:Thailand rdf:type :AsianCountry .
:Thailand :capital :Bangkok .
In this example, it is impossible for RDF2vec to learn that
Berlin is more similar to
Paris than to
Bangkok, since the entities
EuropeanCountry and
AsianCountry never co-occur in any walk with the city entities. Therefore, injection structural information into RDF2vec may improve the results.
- Liang et al. have proposed an approach for using such structural information by injecting them in the loss function of the downstream task (not the one used for training the embeddings per se). Their results show that the performance of entity classification with RDF2vec can be improved by adding a loss term based on structural similarities.
Knowledge Graphs usually do not contain negative statements. However, in cases where negative statements are present, there are different ways of handling them in the embedding creation.
- One variant is the encoding of negative statements with specific relations, an approach which can be used with arbitrary embedding methods. When dealing with walk-based methods on large hierarchies, it is possible to encode the negative statements in the direction of walks along the hierarchy, as demonstrated in the TrueWalks approach in [Sousa et al., 2023].