Evaluation
We have evaluated RDF2vec Light using the GEval framework.
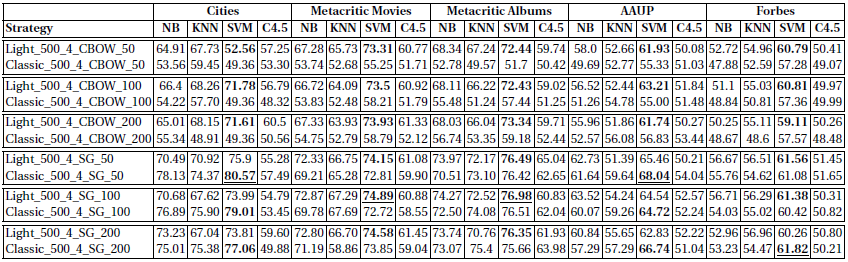
The framework defines a set of classification and regression tasks, as well as entity similarity (KORE) and document similarity (LP5) tasks. The classification results (accuracy) with different classifiers look as follows:
The regression results (RMSE) with different regressors look as follows:
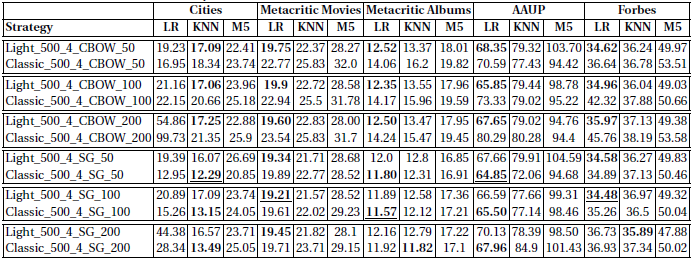
It can be observed that, with eception to the cities case, the best results achieved with classic RDF2vec and with RDF2vec light are quite comparable.
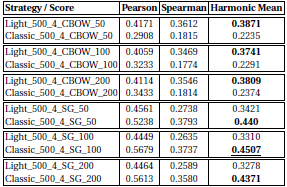
For the tasks on entity similarity, we see a stronger deviation of RDF2vec Light when compared to classic RDF2vec:
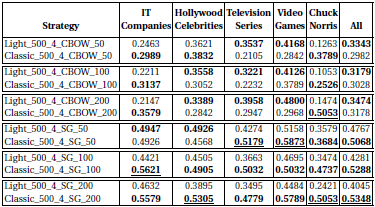
Likewise, for the document similarity, a gap between RDF2vec Light and classic RDF2vec can be observed:
What distinguishes the cases where RDF2vec Light is comparable to classic RDF2vec to those where it is not?
There are basically two indicators: homogeneity and linkage degree. For the classification and regression tasks, the entities at hand are rather homogenous (i.e., cities, movies, etc.), whereas in the entity and document similarity tasks, they are more diverse. Looking at the cities dataset, cities are among the entities with comparable high degrees, compared to, e.g., movies and albums. The entity and document similarity tasks contain a lot of head entities, which have a high degree, whereas some of the other datasets also contain less prominent entities.
Both observations can be made when looking at the graphs which are spanned by the walks performed by RDF2vec Light:
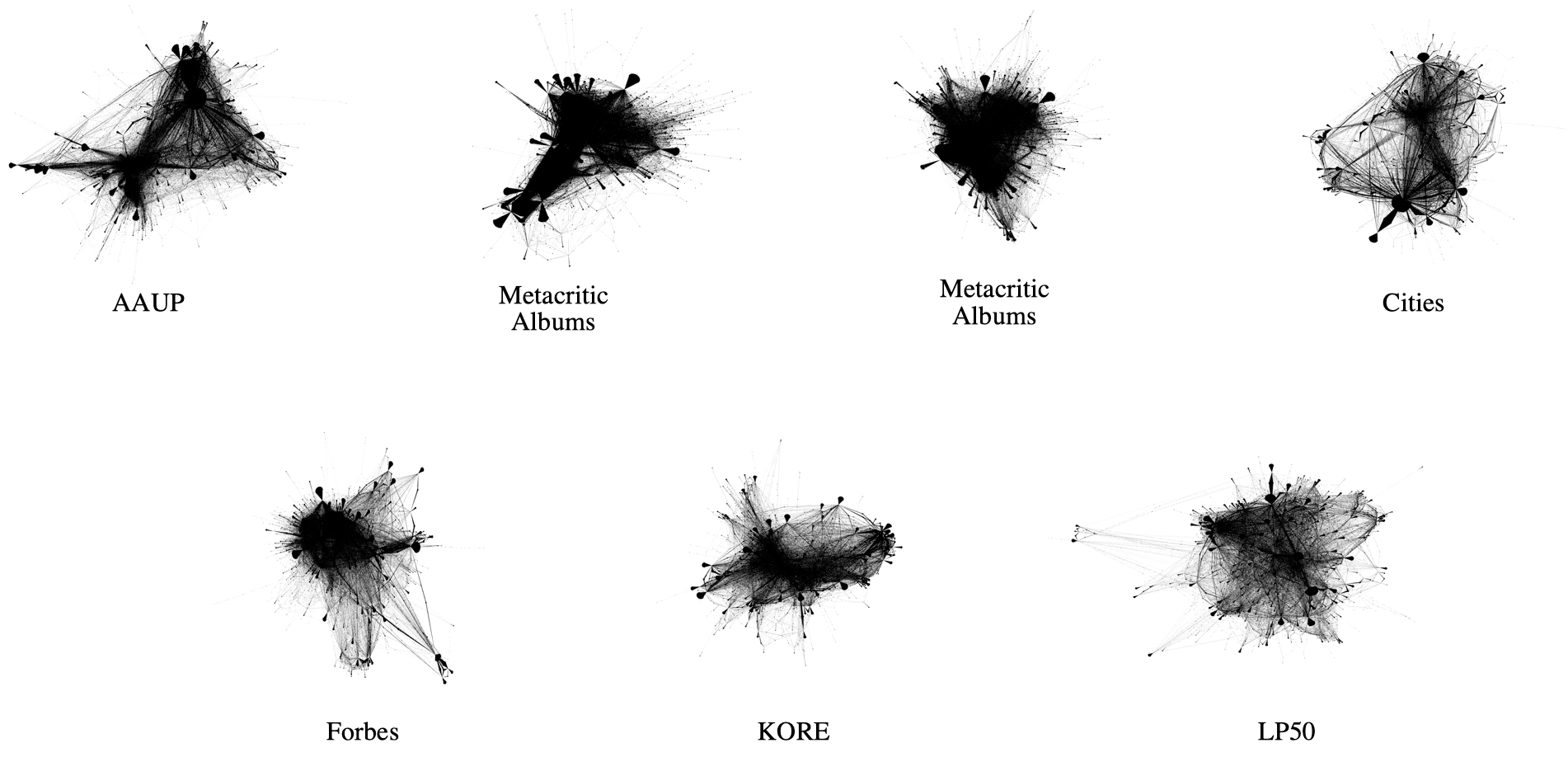
The image shows that the cases where RDF2vec Light walks better lead to comparably dense graphs, which can be explained by the lower linkage degree of the entities at hand, as well as their homogeneity (they have a higher likelihood to be connected to the secondary entities).
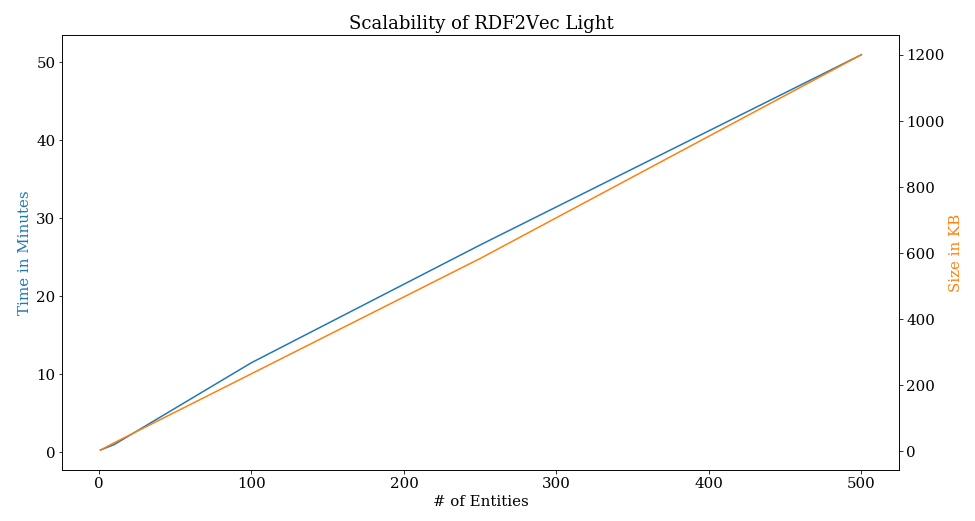
How fast is RDF2vec Light?
RDF2vec Light scales linearly with the number of entities of interest, both with respect to runtime as well as resulting model size. On commodity hardware, those entities are roughly processed at a rate of 10 entities per minute. On stronger hardware, there are quite a few opportunities for optimization (e.g., parallel generation of the walks).